

Natural language can take the shape of text or speech and Machine Learning can be used to solve problems involving the human natural language both in form of text and speech. This is known as Natural Language Processing and it already has lots of fascinating real-world applications.
UNDERSTANDING NATURAL LANGUAGE PROCESSING PROBLEMS
Unstructured texts, such as articles, news, reviews, or comments, are common sources of natural language data. From the unstructured data, useful information must be retrieved. There are a series of steps we must complete in order to retrieve this useful data.
In this article, we'll use the Natural Language Toolkit (NLTK), a python package, as well as Jupyter notebooks to demonstrate the conventional procedures we'll need to take to extract this useful data. The Anaconda package comes preloaded with these packages, so you may install it.
These steps include:
1. TOKENIZATION
This is the process of breaking down multiple phrases or paragraphs into smaller components, such as individual sentences or words. To carry out this step, we need to import the NLTK library and download punkt
import nltk
nltk.download('punkt')
The sent tokenizer and word tokenizer are then imported to generate sentence and word tokens, respectively. We will use this to tokenize a sentence and the result is shown below
from nltk.tokenize import sent_tokenize, word_tokenize
The sample text used is
'Mary had a little lamb. Her fleece is white as snow'
text = 'Mary had a little lamb. Her fleece is white as snow'
sents = sent_tokenize(text)
print(sents)
and the result of the sentence tokenizer is shown below
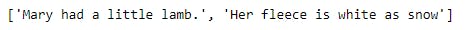
Using the word tokenizer on the same sentence
words = word_tokenize(text)
print(words)
The result of the word tokenizer is shown below
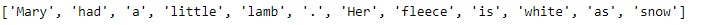
2. STOP WORDS REMOVAL
Stop words are removed after the sentence has been tokenized. Stop words are words that are employed for structural and grammatical purposes but do not provide sense to the text. Examples of such word is 'is', 'for, etc. In other to remove stop words, we need to download the stopwords in nltk. An example is shown below
# Downloading the stop words
nltk.download('stopwords')
# Importing the downloaded stopwords
from nltk.corpus import stopwords
# Importing punctuations in other to also remove them from the sentence
from string import punctuation
# Creating a custom stopwords by adding the list of punctuation to the stopwords
custom_stop_words = set(stopwords.words('english')+list(punctuation))
print(custom_stop_words)
Below is the list of the custom stopwords created

# sentence to remove stop words from
text = 'Mary had a little lamb. Her fleece is white as snow'
# Creating list of words without stopwords
# Code below means to return each word in the tokenized word, if the words cant be found in the custom stop words
words_without_stopwords = [word for word in word_tokenize(text) if word not in custom_stop_words]
print(words_without_stopwords)
The result of the code above is shown below

From the result, we can see that words such as had, a , is, and as has not been included in the result as they do not add meaning to the sentence but structure.
3. N-GRAMS
This entails identifying a set of terms that are found together. In an article on "Rolls Royce," for example, the terms "Rolls" and "Royce" will almost certainly appear together. If "Rolls Royce" is preserved as a single entity, more meaning may be derived from the language. The number of words in a collection of words is measured in n-grams, which can be bi-grams, tri-grams, and so on. an example of n-grams is shown below.
from nltk.collocations import *
bigram_measures = nltk.collocations.BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(words_without_stopwords)
# Bi-grams
sorted(finder.ngram_fd.items())
the result of the bigram is

and for tri-grams
find = TrigramCollocationFinder.from_words(words_without_stopwords)
sorted(find.ngram_fd.items())
The result is shown below

4. STEMMING
Words with the same basic meaning may be written differently depending on the tense and structure of the context in which they are used. Close, closing, and closed are examples of such terms. Stemming is the process of returning all of these words to their root word and having the computer treat them all the same. To illustrate stemming, we will be using a different sentence and the lancaster stemmer as shown below
# New text to be used
text_2 = 'Mary closed on closing night when she was in the mood to close.'
from nltk.stem.lancaster import LancasterStemmer
st = LancasterStemmer()
stemmed_words = [st.stem(word) for word in word_tokenize(text_2)]
print(stemmed_words)
The results of the stemming is shown below and as we can see the words 'closed', 'closing' and 'close' are returned to the root word 'clos' and thus the computer will treat them the same way.
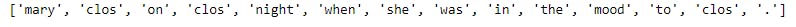
5. PART OF SPEECH TAGGING
How a computer determines if a word in a phrase is a noun, verb, pronoun, or other part of speech. In other to illustrate this, we will use the NLTK to download 'averaged_perceptron_tagger' as shown below
nltk.download('averaged_perceptron_tagger')
nltk.pos_tag(word_tokenize(text_2))
The result is shown below and as we all know, Mary is a proper noun, closed a verb, etc, as they have been tagged

5. WORD SENSE DISAMBIGUITY
This is how a computer interprets a word's meaning based on the context in which it is used. Some words have varied connotations depending on the situation. Depending on the context, the term "current" can refer to both the flow of the ocean and anything modern. To illustrate this, we will download the wordnet using nltk and we will be using the wordnet to check the meaning of the word "bass"
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
for ss in wn.synsets('bass'):
print(ss, ss.definition())
From the result shown below, the word bass has several meaning ranging from 'the lowest part of the musical range' to 'the lean flesh of a saltwater fish of the family Serranidae'

We will illustrate an example to determine if the wordnet can determine the meaning of the word based on the context
from nltk.wsd import lesk
sense_1 = lesk(word_tokenize('sing in a lower tone, along with the bass.'), 'bass')
print(sense_1, sense_1.definition())
The output is shown below and the wordnet is able to determine the meaning of the word based on the context

Showing another example
sense_2 = lesk(word_tokenize('This sea bass was really hard to catch.'), 'bass')
print(sense_2, sense_2.definition())
The result for these is shown below

These are the 5 common activities carried out before training a model for natural language processing.
The code for this article can be found on my Github repository here
Should you have any questions, feel free to send me a mail at olayemibolaji1@gmail.com